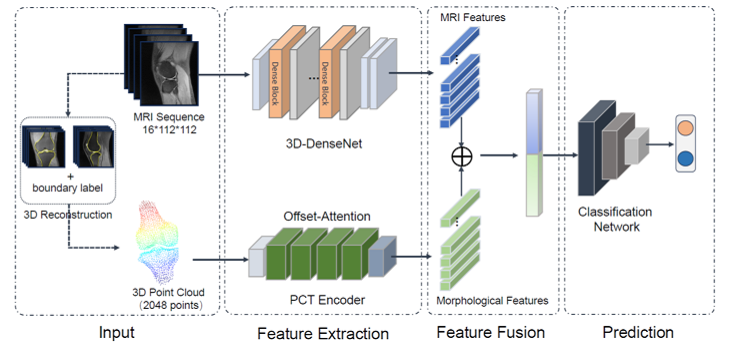
在大數據處理的復雜流程中,數據預處理與數據處理技術扮演著至關重要的基石角色。原始數據往往充斥著噪聲、缺失值、不一致和冗余信息,直接進行分析如同在沙土上建造高樓,結果必然不可靠。因此,數據預處理旨在通過一系列技術手段,將“臟數據”轉化為高質量、可用于分析的“干凈數據”,其核心目標是為后續(xù)的數據挖掘、機器學習與智能決策提供堅實的數據基礎。
一、數據預處理的核心步驟
數據預處理是一個系統(tǒng)性工程,通常包含以下幾個關鍵環(huán)節(jié):
- 數據清洗(Data Cleaning):這是預處理的第一步,也是最耗時的一步。其主要任務是處理數據中的“臟”問題,包括:
- 處理缺失值:對于數據中的空白或無效記錄,可采用刪除法(直接刪除缺失記錄)、填充法(用均值、中位數、眾數或通過模型預測進行填充)或插值法進行處理。
- 處理噪聲數據:識別并平滑數據中的異常點或錯誤值,常用方法有分箱(通過考察數據的“近鄰”來平滑數據值)、回歸(通過擬合函數來平滑數據)和聚類(將類似的值聚集在一起以識別離群點)。
- 糾正不一致:統(tǒng)一數據格式、單位和編碼,例如將日期統(tǒng)一為“YYYY-MM-DD”格式,或將“男/女”與“M/F”進行標準化。
- 數據集成(Data Integration):大數據往往來源于多個異構的數據源,如數據庫、數據倉庫、日志文件、傳感器網絡等。數據集成需要將這些來源不同、格式各異、標準不一的數據合并成一個一致的數據存儲(如數據倉庫或數據湖)。其關鍵技術包括實體識別(判斷不同數據源中的記錄是否指向同一現實實體)、冗余檢測與處理,以及解決數據值沖突。
- 數據變換(Data Transformation):將數據轉換成更適合挖掘的形式。常見變換包括:
- 規(guī)范化(Normalization):將屬性數據按比例縮放,使之落入一個特定的區(qū)間(如[0,1]或[-1,1]),以消除不同特征量綱的影響。常用方法有最小-最大規(guī)范化、Z-score標準化等。
- 離散化(Discretization):將連續(xù)型屬性值劃分為若干區(qū)間,用區(qū)間標簽或概念分層來替代實際數據值。例如,將年齡“連續(xù)值”離散化為“青年”、“中年”、“老年”。
- 屬性構造:通過已有屬性構造新的屬性,以更好地刻畫數據特征,提高后續(xù)分析的精度。例如,在零售數據中,由“單價”和“數量”構造“銷售額”這一新屬性。
- 數據歸約(Data Reduction):大數據集往往規(guī)模巨大,直接處理成本高昂。數據歸約旨在保持數據完整性的前提下,盡可能縮減數據規(guī)模,從而提高后續(xù)處理的效率。主要技術有:
- 維度歸約(降維):減少所考慮的隨機變量或屬性的個數。主成分分析(PCA)和線性判別分析(LDA)是經典的降維技術,它們能夠將高維數據投影到低維空間,同時保留最重要的數據變異信息。
- 數量歸約:用替代的、較小的數據表示形式替換原始數據,例如通過抽樣技術生成數據子集,或使用聚類、直方圖等模型來代表數據。
- 數據壓縮:使用編碼機制(如小波變換)壓縮數據,減少存儲空間。
二、關鍵數據處理技術
在預處理之后,高效的數據處理技術是駕馭海量數據的引擎。這些技術主要解決數據的存儲、計算與查詢問題。
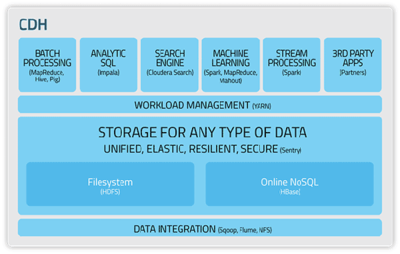
- 分布式存儲技術:
- Hadoop HDFS:作為Hadoop生態(tài)系統(tǒng)的基石,HDFS(分布式文件系統(tǒng))采用主從架構,將大文件分割成塊(Block)并分布式存儲在集群的多個節(jié)點上,提供了高容錯性和高吞吐量的數據訪問能力,非常適合一次寫入、多次讀取的場景。
- 分布式計算框架:
- MapReduce:一種經典的編程模型,用于大規(guī)模數據集的并行運算。其核心思想是“分而治之”,將計算任務分為Map(映射)和Reduce(歸約)兩個階段,非常適合處理離線批處理任務。
- Spark:相對于MapReduce基于磁盤的計算,Spark引入了彈性分布式數據集(RDD)概念,將中間結果緩存于內存中,使得迭代計算和交互式查詢的性能提升了一個數量級。Spark Streaming、Spark SQL等組件也使其能夠處理流數據和結構化數據查詢。
- 流數據處理技術:
- 對于物聯網、實時監(jiān)控等場景產生的連續(xù)、無界的數據流,需要實時或近實時處理。Apache Storm、Apache Flink和Spark Streaming是主流的流處理框架。它們能夠以低延遲處理持續(xù)流入的數據,并進行窗口聚合、事件模式檢測等復雜計算。
- NoSQL與NewSQL數據庫:
- 為應對大數據多樣性(Variety)和高并發(fā)讀寫的挑戰(zhàn),突破了傳統(tǒng)關系型數據庫的限制。NoSQL數據庫(如鍵值存儲Redis、文檔數據庫MongoDB、列族數據庫HBase、圖數據庫Neo4j)在數據模型和擴展性上更加靈活。而NewSQL數據庫(如Google Spanner, TiDB)則試圖在保持SQL和ACID事務特性的獲得與NoSQL類似的水平擴展能力。
###
數據預處理與數據處理技術共同構成了大數據價值挖掘的“前處理車間”和“動力系統(tǒng)”。沒有高質量的預處理,分析結果將失之毫厘,謬以千里;沒有高效、可擴展的處理技術,海量數據的價值就無法被及時釋放。隨著數據規(guī)模的持續(xù)膨脹和應用場景的日益復雜,這兩類技術仍在不斷演進,與人工智能、云計算的結合也愈發(fā)緊密,持續(xù)推動著大數據產業(yè)向更深、更廣的領域邁進。